[May'24]
Car Detection Using YOLO
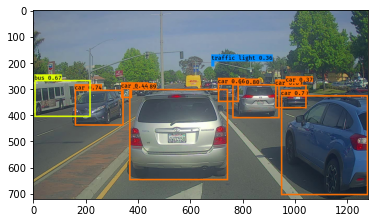
You are working on a self-driving car. Go you! As a critical component of this project, you'd like to first build a car detection system. To collect data, I've used a dataset where a mounted camera to the hood (meaning the front) of the car, takes pictures of the road ahead every few seconds as it drive around. I've gathered all these images into a folder and labelled them by drawing bounding boxes around every car you found. Here's an example of what bounding boxes look like:
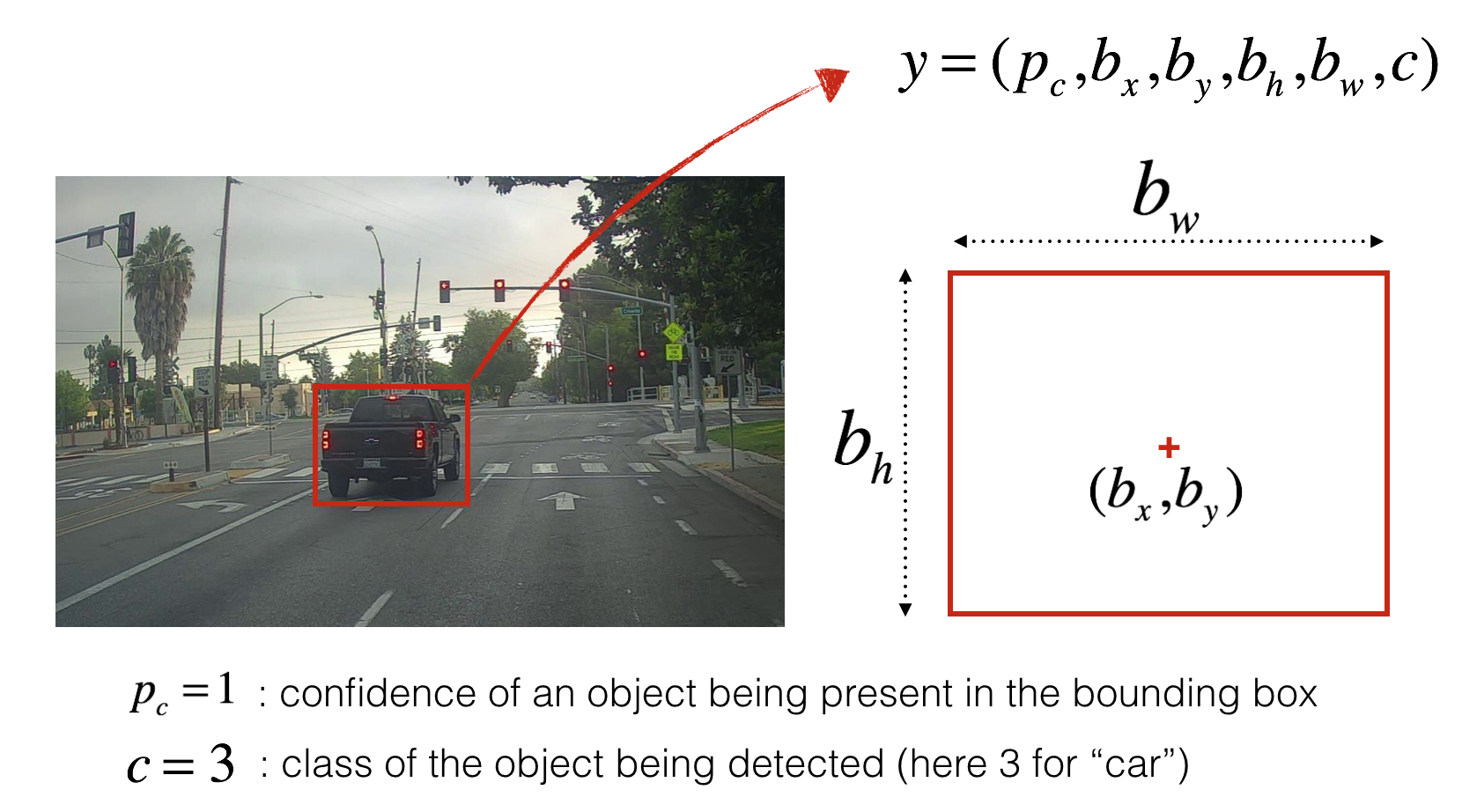
There are 80 classes you I the object detector to recognize, they are represented as the class label c either as an integer from 1 to 80, or as an 80-dimensional vector (with 80 numbers) one component of which is 1, and the rest of which are 0. The video lectures used the latter representation; in this notebook, you'll use both representations, depending on which is more convenient for a particular step.
Why YOLO?
"You Only Look Once" (YOLO) is a popular algorithm because it achieves high accuracy while also being able to run in real time. This algorithm "only looks once" at the image in the sense that it requires only one forward propagation pass through the network to make predictions. After non-max suppression, it then outputs recognized objects together with the bounding boxes.
Model Details
Inputs and Outputs
The input is a batch of images, and each image has the shape (608, 608, 3). The output is a list of bounding boxes along with the recognized classes. Each bounding box is represented by 6 numbers (pc, bx, by, bh, bw, c) as explained above. If you expand c into an 80-dimensional vector, each bounding box is then represented by 85 numbers.
Anchor Boxes
Anchor boxes are chosen by exploring the training data to choose reasonable height/width ratios that represent the different classes. For this assignment, 5 anchor boxes were chosen (to cover the 80 classes). The dimension of the encoding tensor of the second to last dimension based on the anchor boxes is (m, nH, nW, anchors, classes).
YOLO Architecture
The YOLO architecture is: IMAGE (m, 608, 608, 3) -> DEEP CNN -> ENCODING (m, 19, 19, 5, 85).
Encoding
Let's look in greater detail at what this encoding represents.
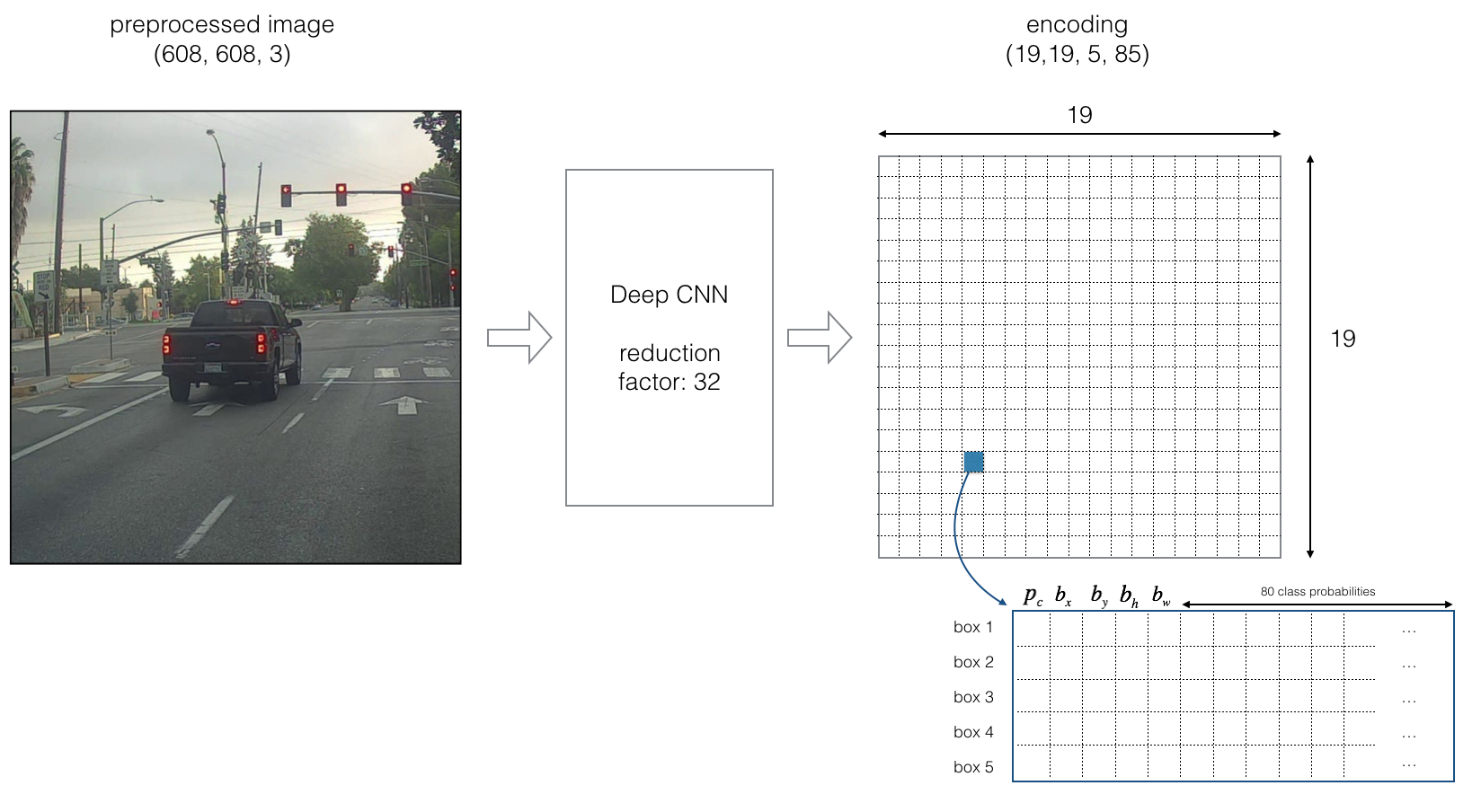
If the center/midpoint of an object falls into a grid cell, that grid cell is responsible for detecting that object.
Visualizing Bounding Boxes
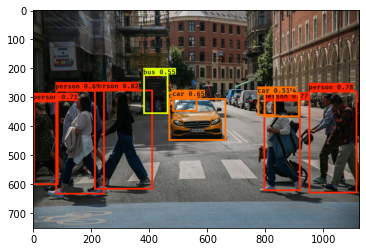
Another way to visualize YOLO's output is to plot the bounding boxes that it outputs. Doing that results in a visualization like this:

Each cell gives you 5 boxes. In total, the model predicts: 19x19x5 = 1805 boxes just by looking once at the image (one forward pass through the network)! Different colors denote different classes.
Non-Max Suppression
In the figure above, the only boxes plotted are ones for which the model had assigned a high probability, but this is still too many boxes. So to reduce the algorithm's output to a much smaller number of detected objects.
To do so, I've used non-max suppression. Specifically, carried out these steps:
- Get rid of boxes with a low score. Meaning, the box is not very confident about detecting a class, either due to the low probability of any object, or low probability of this particular class.
- Select only one box when several boxes overlap with each other and detect the same object.

Summary for YOLO
- Input image (608, 608, 3)
- The input image goes through a CNN, resulting in a (19, 19, 5, 85) dimensional output.
- After flattening the last two dimensions, the output is a volume of shape (19, 19, 425):
- Each cell in a 19x19 grid over the input image gives 425 numbers.
- 425 = 5 x 85 because each cell contains predictions for 5 boxes, corresponding to 5 anchor boxes, as seen in lecture.
- 85 = 5 + 80 where 5 is because (pc, bx, by, bh, bw) has 5 numbers, and 80 is the number of classes we'd like to detect
- Few boxes are selected based on:
- Score-thresholding: throw away boxes that have detected a class with a score less than the threshold
- Non-max suppression: Compute the Intersection over Union and avoid selecting overlapping boxes
This gives the YOLO's final output.