[Jun'24]
Trigger Word Detection with Continuous Temporal Classification using Deep Learning
Trigger word detection is the technology that allows devices like Amazon Alexa, Google Home, Apple Siri, and Baidu DuerOS to wake up upon hearing a certain word. For this project, the trigger word is "activate". Every time it hears "activate", it makes a "chiming" sound.
In this project, I learned to:
- Structure a speech recognition project
- Synthesize and process audio recordings to create train/dev datasets
- Train a trigger word detection model and make predictions
1. Data Synthesis: Creating a Speech Dataset
A speech dataset should ideally be as close as possible to the application environment. In this case, the goal is to detect the word "activate" in various environments such as libraries, homes, offices, and open-spaces. To achieve this, I used recordings with a mix of positive words ("activate") and negative words (random words other than "activate") with different background sounds.
1.1 - Listening to the Data
One of my friends helped by recording background noises in various settings like libraries,
cafes, restaurants, homes, and
offices. The dataset includes people speaking in a variety of accents. The raw_data
directory contains subsets of raw audio files of positive words, negative words, and background
noise, which are used to synthesize a dataset for training the model.
1.2 - From Audio Recordings to Spectrograms
An audio recording is a long list of numbers measuring air pressure changes detected by a microphone. We use audio sampled at 44,100 Hz, meaning the microphone gives 44,100 numbers per second. A 10-second audio clip is represented by 441,000 numbers. To help the sequence model learn to detect trigger words, we compute a spectrogram of the audio, which tells us how much different frequencies are present in an audio clip at any moment in time.
Here is a figure illustrating the labels in a clip where we have inserted "activate", "innocent", "activate", and "baby". Note that the positive labels "1" are associated only with the positive words.

2. Building the Model
The goal is to build a network that will ingest a spectrogram and output a signal when it detects the trigger word. This network uses four layers:
- A convolutional layer
- Two GRU layers
- A dense layer
Here is the architecture used.
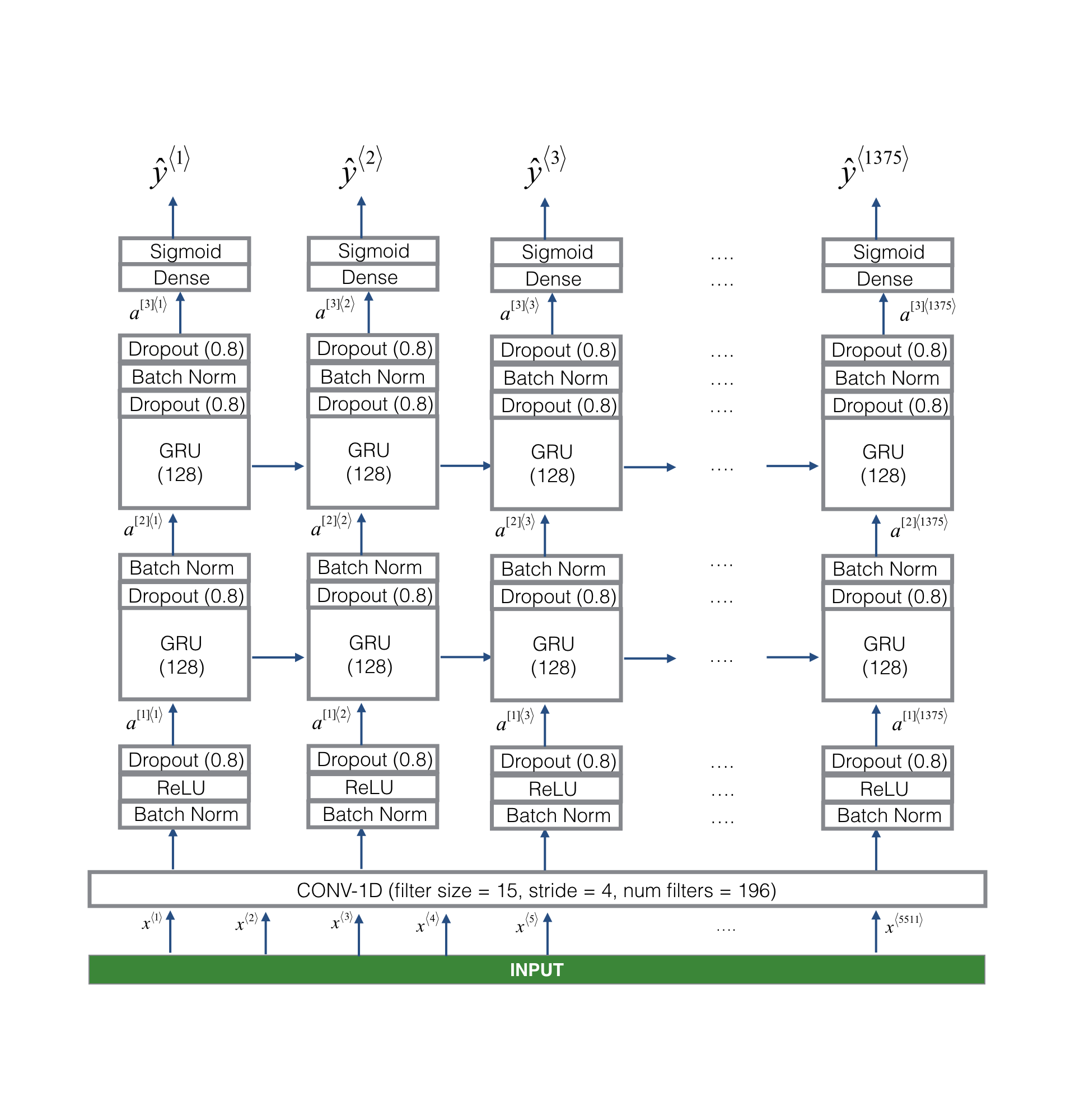
2.1 - 1D Convolutional Layer
The 1D convolutional layer inputs the 5511 step spectrogram, each step being a vector of 101 units. It outputs a 1375 step output, which is further processed by multiple layers to get the final 1375 step output. This layer helps speed up the model by reducing the number of timesteps the GRU needs to process from 5511 to 1375.
2.2 - GRU, Dense, and Sigmoid
The two GRU layers read the sequence of inputs from left to right. A dense plus sigmoid layer makes a prediction for \(y^{\langle t \rangle}\). Since \(y\) is a binary value (0 or 1), a sigmoid output at the last layer estimates the chance of the output being 1, corresponding to the user having just said "activate".
2.3 - Unidirectional RNN
We use a unidirectional RNN instead of a bidirectional RNN. This is important for trigger word detection as we want to detect the trigger word almost immediately after it is said. A bidirectional RNN would require the whole 10 seconds of audio to be recorded before determining if "activate" was said in the first second.
The total number of parameters in the model is 523,329, with 522,425 trainable and 904 non-trainable parameters.